

In recent years, the growth of technologies like Artificial Intelligence, Machine Learning, and Cloud Computing has led to the generation of massive amounts of data. The rise of data-driven technologies has also triggered the need for more powerful computer hardware architecture. More and more cores are being integrated onto single processor chips in order to create powerful processors capable of handling the processing and performance demands of data-intensive applications. However, memory bandwidth and density have lagged behind increasing CPU core count, leading to a gap between the processor and memory performance.
The insatiable demand for memory density and bandwidth is pushing the limits of existing memory technologies. Conventional DRAM design limits the scaling of memory capacity beyond a certain range, requiring an entirely new memory interface technology. What’s more, the rise of AI and Big Data has fueled the trend towards heterogeneous computing, where multiple processors of different types work in parallel to process massive volumes of data.
In light of these trends, a next-generation interconnect technology is essential for heterogeneous computing and composable infrastructure, to enable efficient resource utilization.
What Is Compute Express Link™ (CXL)?
An open standard developed through the CXL™consortium, CXL↗ is a high-speed, low-latency CPU-to-device interconnect technology built on the PCIe physical layer. CXL provides efficient connectivity between the host CPU and connected devices such as accelerators and memory expansion devices.
The CXL transaction layer is made up of three dynamically multiplexed sub-protocols on a single link. These protocols are known as CXL.io, CXL.cache and CXL.mem. When a CXL device is connected to a CXL host, it is discovered, enumerated, configured and managed through CXL.io protocol. CXL.cache enables CXL devices to access processor memory, and CXL.mem enables processors to access CXL device memory. CXL.cache and CXL.mem protocol stacks have been optimized for low latency.
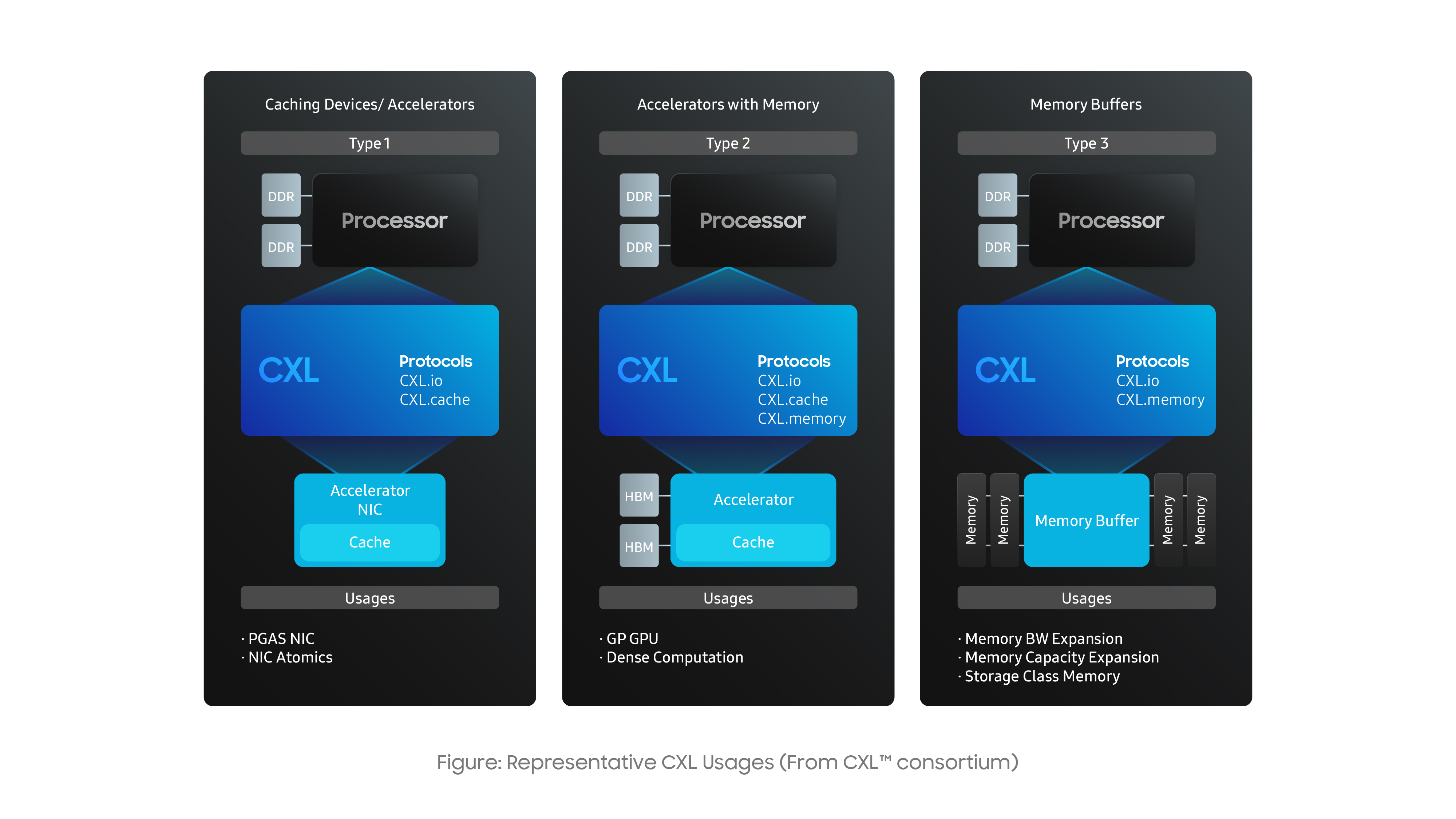
CXL consortium identifies three different device types:
• Type 1 CXL devices are caching devices such as Accelerators and SmartNICs. The Type 1 device can access the host memory through CXL.cache transactions and maintain a local cache that is coherent with the host memory.
• Type 2 CXL devices are GPUs and FPGAs that have memories like DDR and HBM attached to the device. CXL Type 2 devices can directly access the host-attached memory as do CXL Type 1 devices. Additionally, CXL Type 2 devices have local address space that is visible and accessible to the host CPU through CXL.mem transactions.
• Type 3 CXL devices are memory expansion devices that allow host processors to access CXL device memory cache coherently through cxl.mem transactions. CXL Type 3 devices could be used for memory density and memory bandwidth expansion.
For the purpose of this article, we’ll focus on Type 3 CXL devices.
CXL Features and Benefits
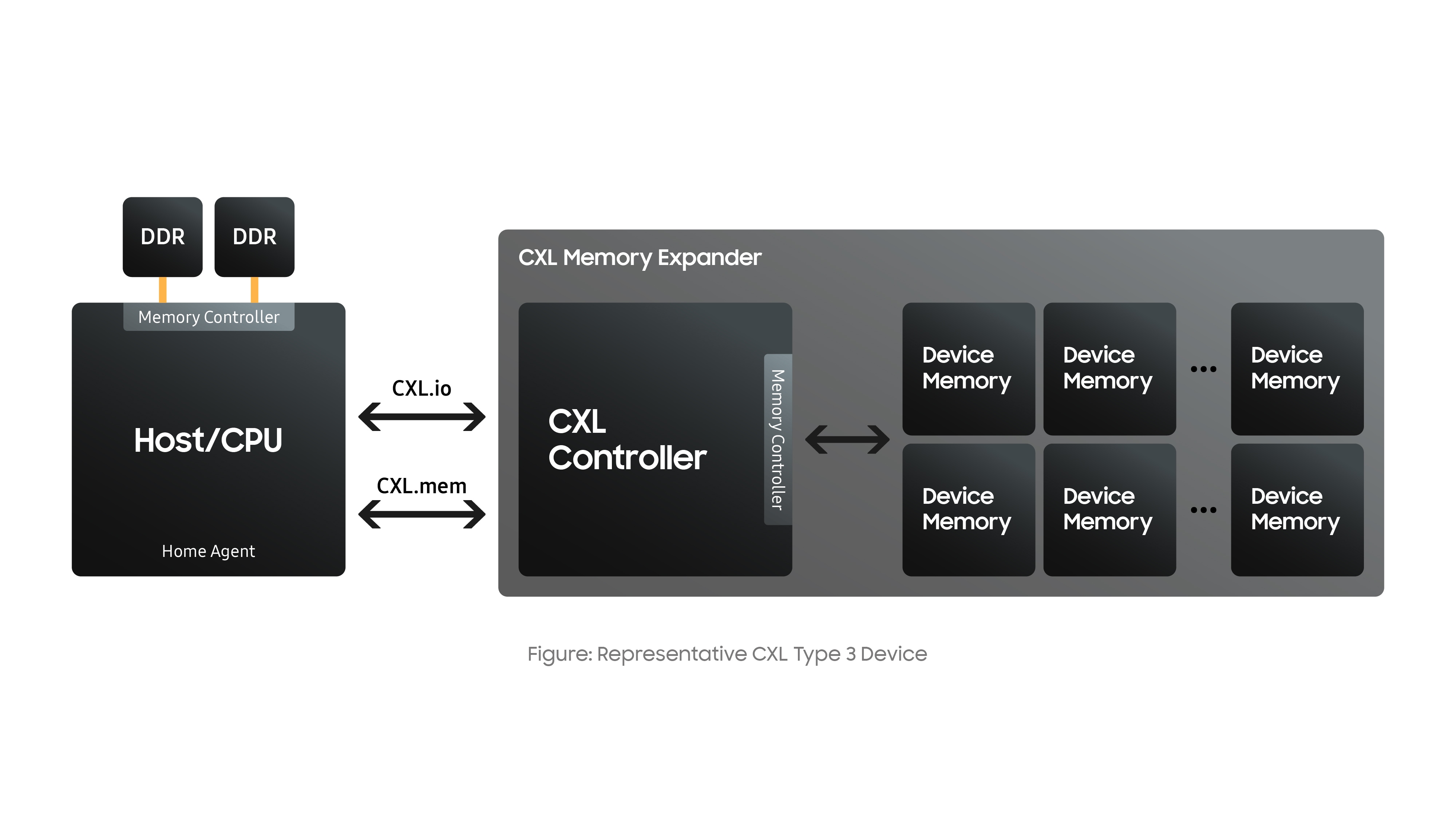
An important feature of CXL is that it maintains memory coherency between the direct attached CPU memory and the memory on the CXL device, which means that the host and the CXL device see the same data seamlessly. The CXL host has a home agent serving as a manager that uses the CXL.io and CXL.mem transactions to access the attached memory coherently.
Why does this matter? Because this enables the CXL host and CXL device to work on shared data and are guaranteed to see the same copy of a memory location. The home agent does not allow simultaneous changes on the data, so once a change is made – either by the host or the attached device – the home agent ensures that all copies of the data remain consistent.
Another major feature of CXL is that it is agnostic of the underlying memory technology as it allows various types of memories (e.g. volatile, persistent, etc.) to be attached to the host through the CXL interface. Moreover, CXL.mem transactions are byte addressable, load/store transactions just like DDR memory. So, attached CXL memory looks like native attached DDR memory to the end application.
The CXL 2.0 specification also supports switching and memory pooling. Switching enables memory expansion, and pooling increases the overall system efficiency by allowing dynamic allocation and deallocation of memory resources. CXL integrity and data encryption define mechanisms for providing confidentiality, integrity and replay protection for data passing through the CXL link.

Traditionally, adding memory capacity and bandwidth in a system involves increasing the number of native CPU memory channels. But adding memory channels to a CPU increases engineering complexity and drives up cost. A CXL Type 3 memory expansion device provides a flexible and powerful option to increase memory capacity and increase memory bandwidth, without increasing the number of primary CPU memory channels.
Samsung’s CXL Memory Expander and Open-Source CXL Software
Samsung introduced the industry’s first CXL Type 3 memory expander prototype in May 2021. This prototype memory expander device has been successfully validated on multiple next-generation server CPU platforms. In addition, the CXL memory expander prototype has been tested on the server systems of multiple end customers with real applications and workloads.
Now, Samsung is testing a new CXL Type 3 DRAM memory expander product built with an application-specific integrated circuit (ASIC) CXL controller – and it’s poised to pave the way for the commercialization of CXL technology. Delivered in an EDSFF (E3.S) form factor, the expander is suitable for next-generation, high-capacity enterprise servers and datacenters.

Samsung’s latest CXL Memory Expander module comes with up to 512GB of DDR5 DRAM memory, which will enable servers to expand their memory capacity to tens of terabytes while increasing memory bandwidth to several terabytes per second. The CXL Memory Expander uses an x8 PCIe 5.0 interface to connect to the CPU with a maximum transfer rate of 32GT/s per lane.
Additionally, Samsung introduced an open-source CXL software solution, the Scalable Memory Development Kit (SMDK). This is a collection of software tools and APIs that enable the main memory and the CXL memory expander to work together seamlessly in a heterogeneous memory system. SMDK enables system developers to easily incorporate CXL memory into advanced systems, without having to modify the existing application environments, thereby accelerating CXL ecosystem enablement.
Samsung’s CXL Memory Expander will be available for early evaluation in Q3 2022, and version 1.1 of the SMDK is available now on GitHub↗.
To learn more about Samsung’s CXL Memory Expansion Solution join Kapil at HPE Discover 2022, June 29, 10 am at Venetian’s Theater #2. Register here↗ today.
